LoL: Using "Personality Quizzes" & Nearest Neighbors for Recommendations
Using AI techniques to map a player’s “personality quiz” into a Champion recommendation in League of Legends (LoL).
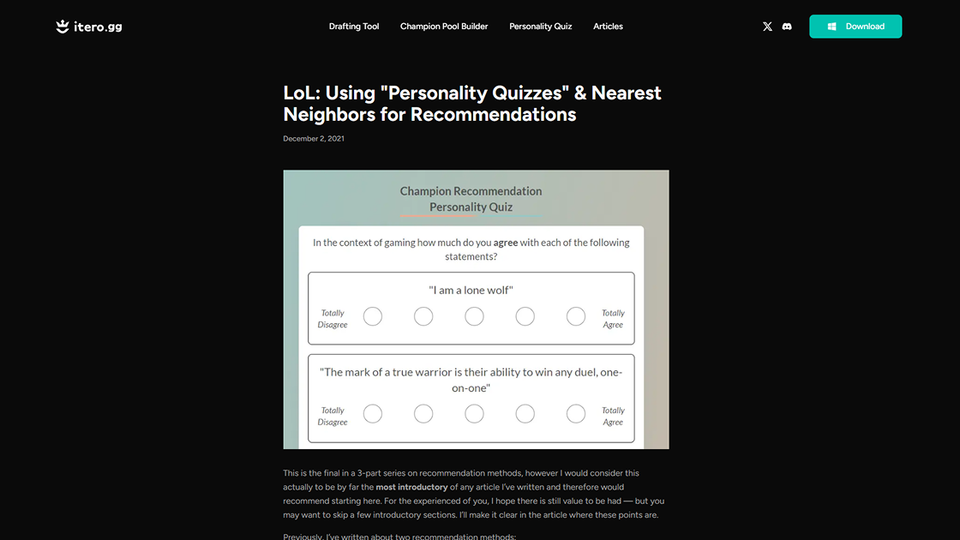


Image Courtesy of PixaBay
In order to prevent the need for me to introduce this model on a regular basis, I instead write this brief article to refer readers who wish to learn more.
iTero Gaming is a UK based start-up which was founded towards the end of 2021, although contributing work has been underway since 2017. It is applying the Latest in Artificial Intelligence (AI) to the Greatest in Esports. What this means is that iTero is building tools & capabilities designed to help take the top esports teams to the next level of performance. One such tool is designed for coaches to more effectively perform “Draft Reviews”…
The first phase of any professional League of Legends game is the “Draft”, also known as “Champion Select” or “Pick & Bans”. Each team will take turns at either banning a Champion, that then cannot be chosen by either side, or choosing one to play. As it stands, there are 158 of such Champions and therefore an immense number of combinations of drafts are possible. However, a much smaller number would be considered as competitive.
There will forever be a debate amongst professionals and the community alike on this topic. It divides critics, rallies supporters and provides fuel to flame. However, in reality the minutiae of drafting is poorly understood. In fact, even some of the more basic principals of drafting are subject to immense debate. The only thing that seems to be fairly well agreed upon is that this phase of the game does impact the probability of either side winning. I’ll let you know by how much I feel it does further down the article.
As a caveat, I do not consider myself the holy grail of drafting knowledge. In fact, I encourage criticism and would invite anyone to mount an attack on any part of my understanding. However, given the amount of time I have spent researching this, not to mention fairly rigorous back testing, I would consider myself currently as close to an expert in the field as one can be.
A Brief History of the Drafting Model
During the 2017 LEC Season I would watch the games and place small wagers on the outcome. I noticed that the these odds would not change once the Champions had been locked in (no longer the case, sorry!). As a player myself I had a strong feeling that this phase of the game must be having at least some impact on its result. And so, I embarked on my journey to predict the results of the games with the addition of the draft. I built the model using MS Excel and it was a horrendous mess, yet given I was adding at least some information I was able to beat the bookies. It was not enough to make regular income, given esports was so new the odds were terrible on both sides. It proved a worthwhile exercise, but ultimately was too much work to keep it updated so I parked it there.
Several years later, I’d learnt Python, finished a Masters in Data Science and worked in the field building predictive models for financial and consultancy organisations. And so, I decided it was time to dust off the old Drafting Model and try again. This time using all the new tools and techniques I’d learnt along the way. Which brings us to today…
Enter both teams draft, predict who will win the game. It’s as simple as that, yet has taken almost a full year to build.
Many questions needed to be answered along the way, such as:
Each of these questions and more were captured as data, investigated and then added to the prediction model. Either it improves the models ability to predict the game, or it does not. This continuous cycle of develop, test then implement was, and continues to be, used to maximise the performance. The ultimate test is whether the model, when evaluating new and unseen games, can beat the bookies once it has been embedded with the drafting information.
The answer? Yes. These numbers are rough and likely to change throughout development, but on average bookies predict the results of the games with c. 63–65% accuracy. Once we embed our additional draft-based data, we predict the results with c. 70–73% accuracy. This means that, ~c.7.5% of a game is influenced by the drafting phase alone. Take this with a pinch of salt.
Personally, I feel that although the model is already considerably complex, there are still missing elements and additional fine-tuning that could yet take this number further. My gut instinct would suggest that someone, at some point, will be able to hit a 15% prediction advantage from draft.
This also may get smaller as time goes on. As more analysts join the discussion this knowledge will be shared more widely, meaning that the advantage will begin to decrease as bookies will start to consider “Which team is good at drafting?”. However, we’re along way off that yet and I hope this provides some inspiration for you to join the fray.
The “model” is actually many different techniques combined into one. Each layer predicting various elements of the game before being ultimately combined into a singular prediction. Some of these are simple linear models whilst others are much more complex non-linear methods such as gradient boosted trees. The evaluation uses train/test/validation splits and is time-split. I.e. if we’re predicting games from June 2021, only games prior to this date will be allowed in the training set.
Here are some other articles that may be of interest.
Using AI techniques to map a player’s “personality quiz” into a Champion recommendation in League of Legends (LoL).
Using AI techniques to classify League of Legends (LoL) Champions into different classes and why this can be useful.

Using AI techniques to simplify Champion playstyles into simple and explainable attributes, useful for classifying them into classes or recommending them to players.
