LoL: Draft of the Week — Team Vitality vs. SK Gaming
The League of Legends (LoL) draft of the week, decided by AI. This week, Team Vitality vs. SK Gaming and the power of winning every lane.
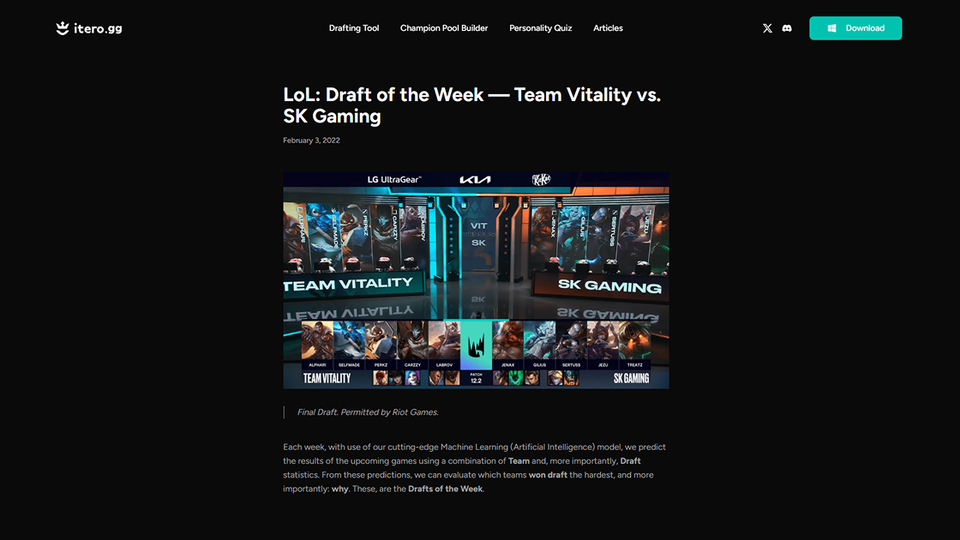


Image provided by PixaBay.
My first role as a Data Scientist was in finance, my job was to build predictive models to estimate the monthly P&Ls. Of course, there was some base value in being able to provide these forecasts to the wider teams as it made all sorts of logistics easier to plan for. However, that wasn’t where the real value lied. The true power of the AI wasn’t its ability to predict the outcome of the status-quo, it was the ability to evaluate how best to change it!
For instance, the single most important feature of the model was the price. Lowering a products cost increased the models’ forecasted sales, but simultaneously would reduce the profit-per-unit. It was the art of balancing these two aspects that made the model worth building. The team responsible for setting the price could consult the models to understand how various scenarios would play out, or even simply ask for the optimal price.
It is exactly the same in esports. If a model’s sole function was to tell you that “Team A had a 75% chance to win the game”, unless you’re a professional gambler this information has little value. There has to be a “so-what?”. An actionable insight. Hopefully, the examples I’ve detailed below will crystallise what I mean by this and provide food for thought.
AI is split into two distinct capabilities, supervised and unsupervised. Prediction falls into the former, where we are providing the model with features (such as price, from my previous example), and a value to predict (such as sales). The model must then learn how best to use these given features to make this prediction. To fairly evaluate how well it has made these predictions, it is good practice to then ask the model to forecast new values using data that has not been used to train it. The “how” ranges from simple linear models such as Linear Regression, to complex “black-box” approaches like Deep Learning. There exist many well-written breakdowns of predictive models and I would recommend further reading if this part is new to you.
One of the most valuable applications of AI in esports is one in which the result of the game is predicted. This could be done days ahead of the match, where the primary features would be team-based, such as recent performance or information about the players. A step above this is a model to predict the results just prior to the game starting. This would contain all the previous features, as well as new esports specific ones like which map is to be played, which side the teams are starting on or which characters/loadouts they’ve chosen. Even more complex models can be built for in-game predictions, incorporating once again all the previous information, as well as new live information like the resources held by the teams at any point in the game.
However, remember that outside of betting the predictions alone offers no value to players or coaches. It’s understanding why and using this information to make better decisions that matters. For instance, let’s say what we are interested in is predicting the results of the game right after the players had chosen which characters they will be playing. If you’re more familiar with FPS games, substitute “characters” for “loadouts”. To do this, the model has been given two features:
It’s likely that two relationships will exist. Firstly, a character who has won 60% of their previous games should be more likely to win than one that has won only their previous 40%. Obvious, right?
As well as this, a player who has won 60% of their games on their character should be more likely to win than one who has only won 40%. Although it may be comforting to know the data agrees with our assumption, we won’t be providing any real value.
In my previously referenced financial model, the power came from being able to optimally trade-off margin and volume. Here, we need to balance the strength of the character with the players ability on it. If we had a character with a 60% recent win rate, but the player has only won 40% of their games on said character, is that a better situation than having a character with a 40% win rate but the player having won 60% of their games on it?
As far as examples go, this is about as basic as it gets. Two variables, both with obvious and fairly straightforward relationships. Yet still, it is not an easy question to answer. Each time we add a new feature to consider it becomes harder still. Yet for AI, this is a cake-walk. It can study thousands of games and learn subtle rules in which one trade-off favours another. Depending on the chosen model, it could even learn the less obvious relationships.
For instance, in most games it benefits to have a healer/medic on the team, which means increasing this variable is positive. However, do you really want to field a team of only supporting roles? How much healing is too much, and does this vary by map, game type or by the strategies employed by your opposition? These questions and many more are faced by coaches on a daily basis and making accurate estimations is also impossible for the human brain.
So, we take all the variables we can think of and we train a model to predict the results of the game. That is one part of a Data Scientists role. However, and arguably more importantly, we must use these models to provide the team with actionable insights. Here are some examples:
“The model says we are likely to lose a lot of our games this season as our mid-range damage statistic is low, during the off-season we should consider buying a player who excels at this role. Here are some of the top players in the league that maximise our win chance.” “The problem with choosing this character is that although it is performing well and our players are comfortable with it, the model believes it will struggle against the oppositions playstyle. This alternative character has a slightly lower win rate but historically is a strong counter to aggressive teams.” “We had a 60% win chance until this part of the game, then it decreases to 40%. This was when we focused on securing Objective A4 whilst allowing the opposition the opportunity to secure B2. The model suggests we could have increased our win chance to 65% if we had focused on defending B2 from their attack instead.”
A model is only as good as its data. This is a problem that traditional sports have been overcoming for years. As much as they wished to deploy AI as quickly as they can, they soon realised that simple statistics like “goals scored” or “home-runs” only produced simple models. What was required was not an advancement in AI, but in data capturing. The ability to take a physical world event like a player sprinting down the left-field, and convert it into detailed data such as pace, stride and an exact position. To do this isn’t cheap. Firstly, the footage needs to be recorded from multiple angles on high-resolution video cameras. This data then needs to be engineered into a usable format before finally being churned through Computer Vision models that can convert millions of images into raw data.
The reason esports is in such a favourable position is that this stage can* be bypassed. Games are usually engineered in a way such that raw information like a player’s position on the map or the abilities their using is being captured by default. Those wishing to work on AI are free to play with the data from the get-go, without all the costly data gathering investment required in traditional sports.
*I write can here as not all game publishers are the same. Some provide data via an API for all who ask for it, others charge a fee whilst some do not release theirs at all.
I hope that thus far, I have provided you with hopeful optimism for the future of a data scientist in esports. However, I must warn you of one flaw before I conclude. This is something that one encounters almost immediately when first investigating the field and will continue to overshadow your work throughout.
Simply put; games change. If you think of traditional board games such as Chess or Go, the rules have remained the same for centuries. If I played against you last year, then it’s safe to assume that the next time we play it will only be us who has differed. This is why AI has so successfully conquered the competitive field. It has had the ability to learn from millions upon millions of games, each following the same rules. Eventually, inevitably, it will learn even the most sophisticated stratagems required to overcome its opponent.
Now, imagine if in Chess each piece would be subject to a new set of random changes each game. Suddenly, Pawns can take a piece directly behind it. The Queen can only be moved every third move. Knights hop two steps forward then two steps to the side. The AI would falter at every change, undoing millions of finely tuned parameters which suddenly barely know how to play the game, let alone win it. This is the situation in which esports finds itself, with the most popular games changing as often as weekly.
Let us say we had our model trained to identify the strongest character (or loadout) to take at the start of the game. Yes, over the last 2 weeks that character had won 60% of their games — but yesterday the game updated and now she does half the damage she used to. Right, so will she still win 60%? Or is it 30%? What happens if you’re the first game after the change with no data to work with? Even so, esports is popular but not that popular and for the most spectated game there will still be at most 50 professionally played games each week with no promise that they’ll even play the character — it will be far from enough data to learn the new impact of the changes.
However, do not give up hope here! Of course, this is a challenge, but not one that cannot be overcome. The final benefit of esports is thus: millions of people play the game everyday! Those professional esports players who find themselves competing on stage each week also return home to play amongst the general population. Just imagine if each day not only were millions of football games played across the country, but all their data was reliably tracked and stored.
Better yet, most games employ a match-making system, allowing for the highest skilled amongst them to play together and the casual newbies to be left alone (in the most part). This allows for data to not only be gathered, but also be hand-picked to include only those who’s games most closely resemble the professional environment.
Of course, these “casual” games will never truly track the professional scene, primarily due to a) players having a lower risk tolerance on stage b) teams have improved coordination, especially if they have a coach. However, that does not and should not stop you working out clever ways to extract insights from this invaluable data source.
Here are some other articles that may be of interest.
The League of Legends (LoL) draft of the week, decided by AI. This week, Team Vitality vs. SK Gaming and the power of winning every lane.
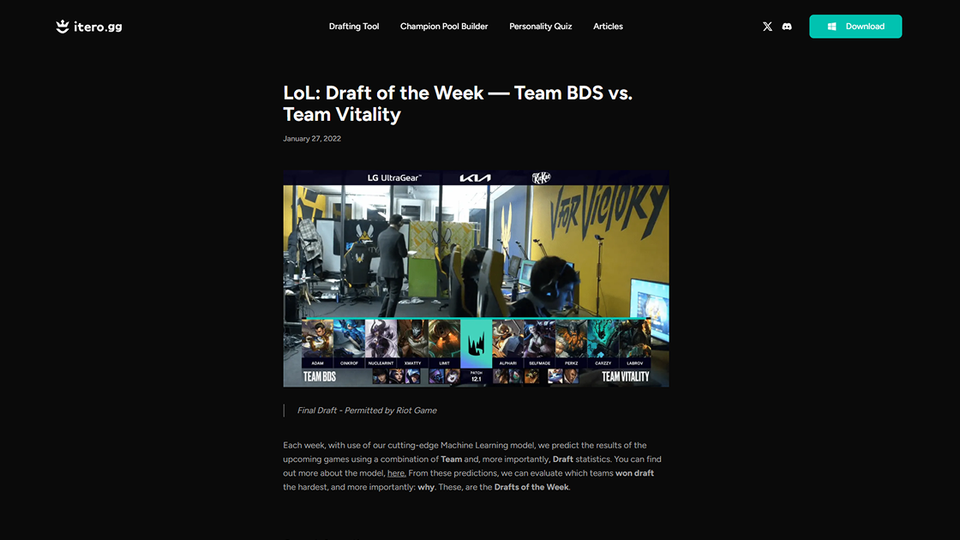
The League of Legends (LoL) draft of the week, decided by AI. This week, Team BDS vs. Team Vitality and the “I run into you” composition.
How AI can be used to optimise a League of Legends (LoL) draft by analysing the meta, player’s skill, counter picks, synergies and more. This specific article speaks of the uses in esports.